Weekly OnCall Rotation
OnCall US Pacific: Leo (leo@harmony.one)
OnCall Asia/EMEA: Soph (soph@harmony.one)
Duration: 11/16 8:30am - 11/23 8:30am PST
Summary
Details
11/16:
- Node OOS: https://harmonyone.pagerduty.com/incidents/Q01U9AN7P81JHI
- Multisig Frontend Down/Up - uptimerobot
- Node OOS: https://harmonyone.pagerduty.com/incidents/Q20MMRAVMY8D5H
- Batch remove all ‘latest/*.gz’ from all nodes to free the disk space on the root volume
11/17:
- Beacon out of sync
- Shard 2 signing power at 75% due to S2 DNS nodes all being out of sync. Fixed by adding more DNS nodes.
11/18:
- Beacon out of sync, had to restart to avoid OOM
- Mainnet BTC indexer sync auto resolved
- Updated grafana to start alerting at 85% cpu usage
- Out of sync issue :
- Updated grafana to start alerting at 85% cpu usage
- Upgraded 9 DNS node from c5.large to c5.2xlarge
- Restarted node
- Validator node :
- Memory Usage Alert: https://harmonyone.pagerduty.com/incidents/Q2ZBVTBBCSH92R
- OOM killer, time to replace nodes (https://github.com/harmony-one/harmony-ops-priv/issues/55 )
11/19:
- Testnet fork issue at block 17732590 fixed by reverting all nodes s1/s2/s3 and s0 explorer node by 1 block
- Memory alert, while pending #55, for now restart of a list nodes …
11/20:
- Disk at 90% : 3 nodes disks were upgraded
All S1/S2/S3 validator nodes are upgraded to r5.xlarge. Old instances will be deleted monday/tuesday.
- Disk upgrade to 750G: (https://harmonyone.pagerduty.com/incidents/Q0FXRPYE2UOLR7 )
11/21:
- Disk at 90% PD Alerts : two nodes were upgraded to 700GB
11/22:
- One node was stuck. Had to restart the harmony process to unblock it
- Multiple s0 RPC node were in general having constantly 5 ~ 20 blocks delays
Those were mainly due to
- The previous stuck node that was lagging behind
- One of the api websocket node was constantly behind
- Screenshot node was still syncing due to daily snapshot occurrence a few hours before
- Asian node all had cpu usage varying between 5% ~ 30% (same zig zag pattern when we had the RPC issue 2-3 weeks ago)
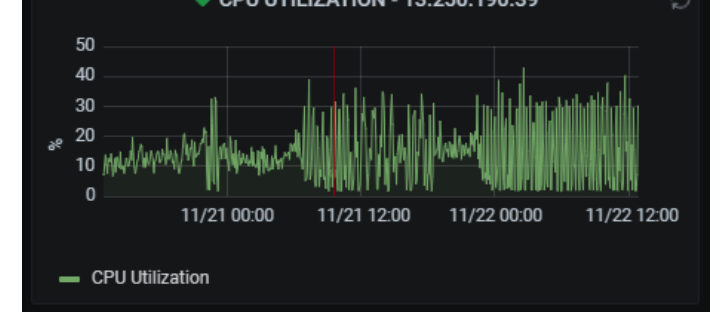
After a while it would eventually go back to normal leaving only the previous stuck node behind :
Unique Blocks: [19669427 19662283]
- Multiple disks at 90%, true-up across all S0 nodes all are now below 70%. Only the snapshot node needs separate work.

Note : Websocket node has been for the past few days always a bit behind 1 ~ 10 blocks, Jack was following on that and did some changes on the target group
Impact on Nov 21 vs. back in Nov 11

11/23:
- 2 s0 RPC node were stuck with no apparent reason, created : Mainnet S0 node got stuck · Issue #3941 · harmony-one/harmony · GitHub
Takeaways:
- Whenever received single alert/alarm, check on similar instances, such as OOS, OOM.
- Testnet bridge alerts and explorer-api-websockets are not being auto-resolved.
- Shard 0 pruned DB is getting bigger and bigger